
      
Object Storage :Harnessing Explosion in Unstructured Data Click on Executive Summary, Table of Contents or IMEX Research for additional information on report.
The new challenges of unstructured data
A Need for New File Storage SolutionsStructured data is most often generated to support a transaction and is then stored in a relational database making it easy for storage managers to understand both the content and context of the data. Since it supports transactions, it is necessary for this data to remain immediately accessible.  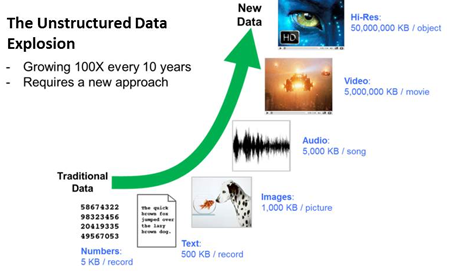
Unstructured information, on the other hand, is often generated at the time of a particular event and stored outside of a database. The difficulty with unstructured data is that there isn’t a mechanism analogous to a database that allows this context to be maintained. Instead, the context is often lost or separated from the data, and storage managers must make decisions based purely on the data type e.g. jpegs. The lack of context and content information make it difficult to understand the value of an unstructured data file and how it needs to be protected and for how long it needs to be retained. This lack of context and content info puts IT managers to take the conservative path – store everything and forever using expensive primary storage and continuously. Given the characteristics of unstructured data, the difficult question facing storage managers is how they can effectively and efficiently store this data and be mindful of both the context around, and the content, within the data to make the right storage decisions.
File systems, designed originally to allow concurrent access to smaller groups, were built to enable both read and write operations; hence they included overhead to manage permissions, and operations such as file locking. Much of the unstructured data that is generated today, does not require concurrent access; so the file systems overhead is unnecessary and simply adds cost and complexity. Using NAS storage for unstructured data means that too high a price is being paid for capacity to store aged or rarely accessed data.
A Restricted Hierarchical File System File systems store data in hierarchical structures (’trees’) consisting of directories and a hierarchy of nested folders, subfolders and files; the content and data contained within a file is not anywhere as important as is the location in the directories; as a consequence each file will have only basic metadata attached to it, such as file name, date created, last modified, file type, and person who created the file. This limited amount of meta-data associated with each file means that IT teams do not have the context and content information they need to efficiently manage and use the unstructured data. This lack of knowledge at the individual file level means instead they must rely on blanket policies that apply across file types (e.g. all JPEG files must be stored indefinitely). As the amount of data grows, so do the number of nested folders. The result is a set of large tree structures that makes it cumbersome and challenging to find any particular file; additionally as the tree structure grows, the performance of the file system starts to degrade and backup becomes more difficult. Needed: A fresh approach called Object Storage Object storage is an approach to storage where data is combined with rich metadata in order to preserve information about both the context and the content of the data. The metadata present in Object Storage gives users the context and content information they need to properly manage and access unstructured data. They can easily search for data without knowing specific filenames, dates or traditional file designations. They can also use the metadata to apply policies for routing, retention and deletion as well as automate storage management. A richer set of metadata can also make it easier to apply eDiscovery and business intelligence tools to help an organization uncover data assets and gain new insights. Object storage helps to ensure that the value of information contained within unstructured data is maximized and preserved for future use. Objects are also useful in directly keeping related information together by enabling multiple file types to be grouped together. For example, in a medical environment, it is possible to group a patient’s MRI images with the physician’s recorded notes (in an MP3 file) along with the text file that has the patient’s history – very similar to the way that information is managed in today’s paper based world where a patient’s file can contain different file types. Technical Attributes of Object Storage An object is also different from a file in that a unique ID is assigned and associated with each object. This ID is generated using a 128-bit random number generator and guarantees that every object is uniquely identified - allowing objects to be stored in an infinitely vast flat address space containing billions of objects without the complexity file systems impose. Similar to the function of URLs in the Internet, an Object ID serves as the unique pointer to the object; hence there is no directory hierarchy (or ’tree’) and the object’s location does not have to be specified in the same way that a file’s directory path has to known in order to retrieve it. The unique identifier also allows objects to be easily migrated from one storage node or system to another without interrupting application or user access if the underlying hardware is being upgraded. The diagram contrasts amount of metadata associated with File vs an Object 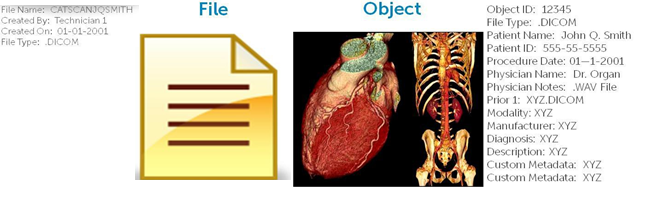
In addition to the unique Object ID a hash signature also has a strong role to play in managing storage for unstructured data, particularly in the removal of duplicates and in helping to address compliance mandates. Since the hash signature associated with each object is generated according to the data contained within the object, if the same signature is recognized as already being in the hash table, it is immediately known that duplicate data exists in the storage system. With this knowledge, storage managers can decide how they want to treat it. Similarly, demonstrating that data has not been tampered with is one of the important requirements where compliance is important. One way to prove this, if required, is to show that the hash signature has not changed. This authentication schema makes Object Storage useful for archiving data while protecting it, and in helping to meet regulatory requirements, particularly for data that has high legal or compliance risk. Object Storage can also be more cost effective than NAS since Object Storage does not require much of the overhead present with NAS to manage inodes, concurrent read/writes, file locks and permissions that improves performance and enables massive scaling in terms of object count and capacity thus companies can simply and affordably scale object storage to petabytes of data – a key advantage as they look to manage the rapidly growing amount of unstructured data. Also storage managers can use the metadata contained within objects to appropriately route to the right storage tier and free up primary storage capacity to reduce cost in comparison to file storage . 
Object Storage and Traditional NAS Coexist 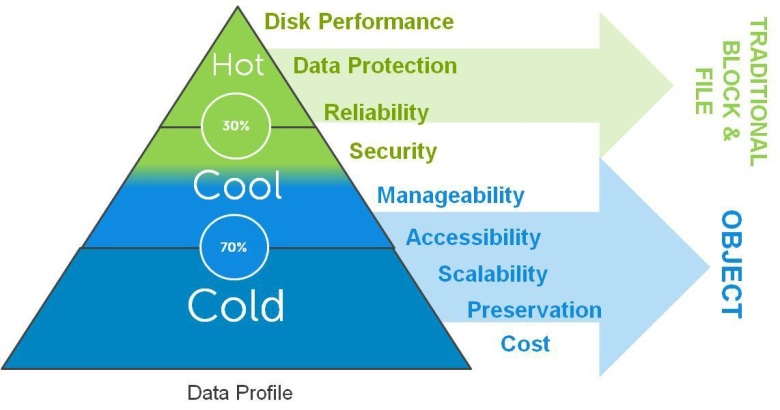
It is estimated that 70% of data generated is never accessed after its initial creation and remains static, while 20% is semi-active. Object Storage fits this category when large numbers (millions or billions) of unstructured data files need to be stored and are relatively little accessed. For the 10% of all data that is actively used, traditional NAS file systems are best suited. both Object Storage and traditional file storage systems have strong roles to play within an organization, depending on the frequency of access, as shown in the diagram. Object vs Tradional Storage Object Storage in Intelligent Data Management One of the primary benefits of Object Storage is the role that it can play in intelligent data management. For storage managers, the mantra they are increasingly working with is to ’store everything’ and ’store it forever.’ The traditional brute force approach to this problem is to continuously throw storage resources at the data. This unfortunately only provides short term relief – with ever growing volumes of data, storage managers find that their budgets are strained trying to keep up. Dell is focused on developing approaches to help organizations intelligently managing data storage is becoming urgent as the explosion of data under management explodes-the key is to automatically route data to the right storage systems and the right tier and protection levels according to its value and stage in the data lifecycle - the most expensive high performance systems reserved for frequently accessed primary data while infrequently accessed secondary data is routed to comparatively less expensive storage. Object Storage, with its rich metadata, can play a significant role in automating Intelligent Data Management for unstructured data by enabling users to apply policies based on metadata values and automatically route data to the right storage systems. Object Storage is a promising solution for managing the complexities of unstructured data and ensuring long-term retention and access that flexibly scales to meet high growth in terms of the number of objects and storage capacity. It uses rich metadata attached to the data allows understanding the content and context of the data. By providing a unique identifier for each distinct data object helps to specifically locate and retrieve data. The separation of the identifier from the hash signature is a powerful tool for enabling deduplication plus a strong authentification tool to meet compliance mandates. Much as all the web scale internet sites and service providers have been using Object Storage since the last 10 years, 2013 was the turning point in major commercial products available from the likes of EMC, NetApp, HDS, IBM and many startups like Data Direct, Scality, Nirvanix, Cleversafe, Cloudian, Amplidata, Caringo and now many new entrants endorsing Open Source like OpenSwift, Basho, Red Hat and others (See IMEX Research’s Object Storage Industry Report 2014) 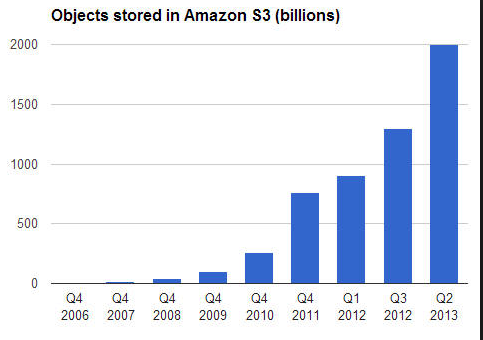 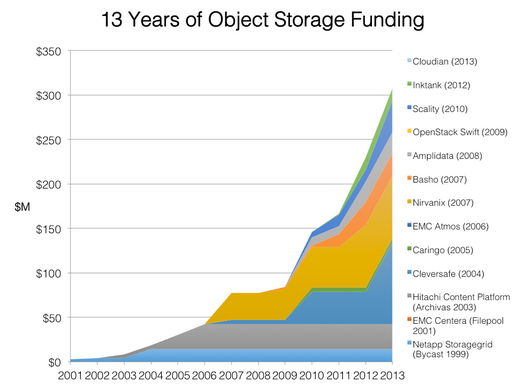
The market for Object Storage Solutions is earmarked for a healthy growth rate of 26% cagr during 2013-2017 and forecasted to reach $27 billion by 2017, much as the established players will own a bulk of it (see market forecast Chapter 4 in IMEX Research’s Object Storage Industry Report 2014) Object Storage is an ideal solution for efficiently managing large unstructured data sets with high compliance and legal risk such as medical and legal records, e‾mail, invoices and financial records. It is also useful in helping to unlock the value of stored content through business intelligence applied to the object’s metadata which optimizes data management by providing the information needed to define policies for intelligently and automatically routing data to the right storage systems and the right tiers to achieve lower costs by freeing up capacity on primary storage and for archiving data Major chapter include 1. Executive Summary 2. Market Drivers and Industry Dynamics 3. Market Segments and Product Requirements 4. Market Forecast and Market Shares 5. Enabling Technologies and Standards 6. Competitive Products and Positioning 7. Major Suppliers Portfolio and Strategies 8. Go-to-Market Distribution Channels 9. Recommendations for Vendors, Channel Players, End Users & Investors plus 10. Methodology and References sections. Click on the following for additional information or go to http://www.imexresearch.com Click for Table of Contents For Overview of Industry Reports click here or click the following icons 







|